We will explore 3 basic concepts of deep neural networks. The first part will explain how back-propagation algorithm works. The second talks about softmax function. And the last one is cost function.
Inside Backpropagation algorithm
The main idea of Backpropagation algorithm is aims to minimize the overall neural network error. To do that, we find out the partial derivative of error and weight vector. Take a look in a simple Neural Network:
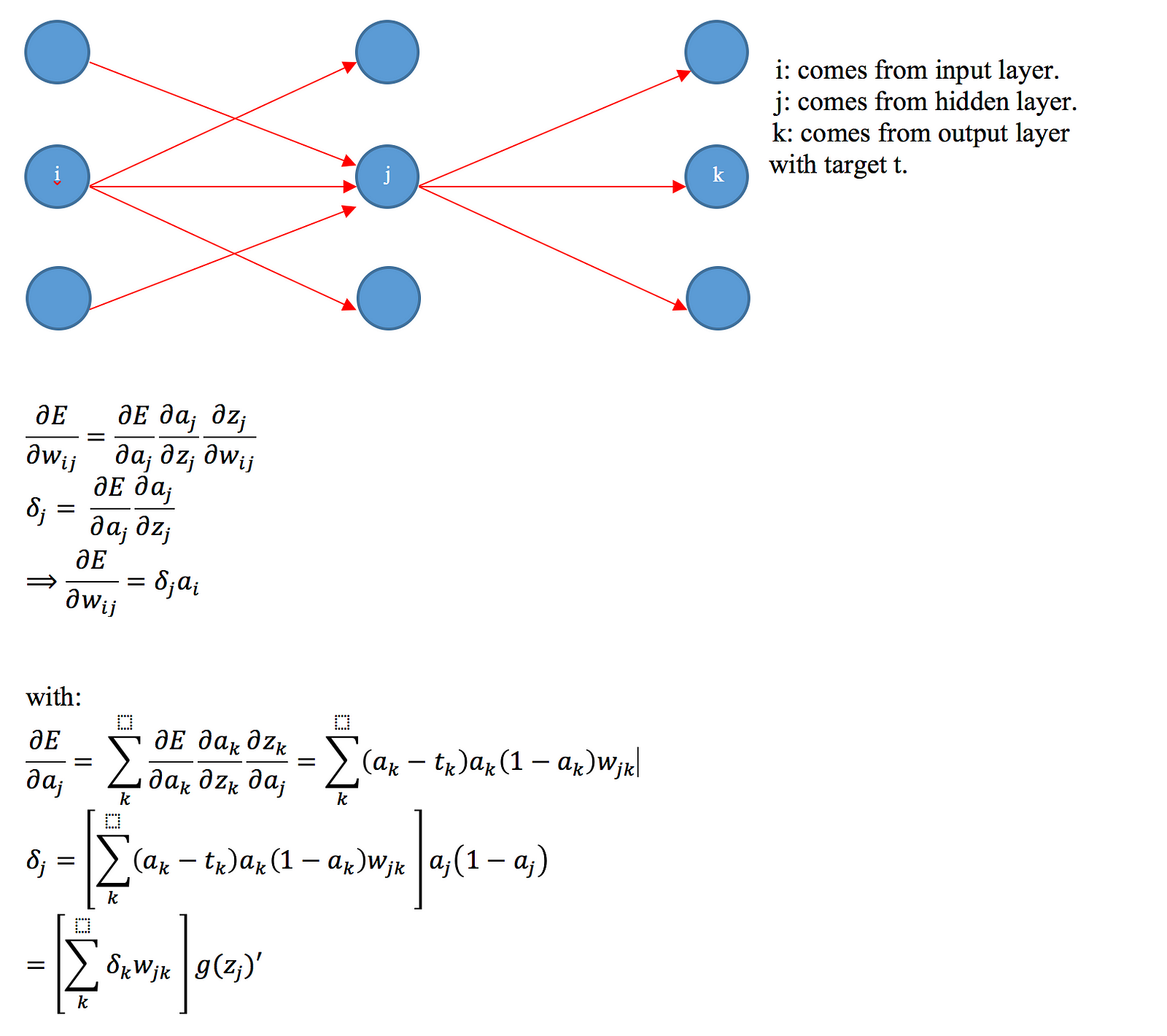
From Sigmoid function to Softmax function and Cross-entropy cost function
In the classification problem with multinomial distribution, how do we know which label is choosen? Softmax function is used to do that. In practice, some people might also use one2All mechanism to detect label by traning many logistic regression models. However, it is not effective solution. Softmax function helps us to determine the label also we can calculate the cost from this easily by using Cross-entropy cost function.
Sigmoid function
Sigmoid function comes from binomial distribution model. There are only label 0 or label 1 occur. In order to train a logistic regression model, we find the weights that maximize the likelihood of the model (log is concave function):
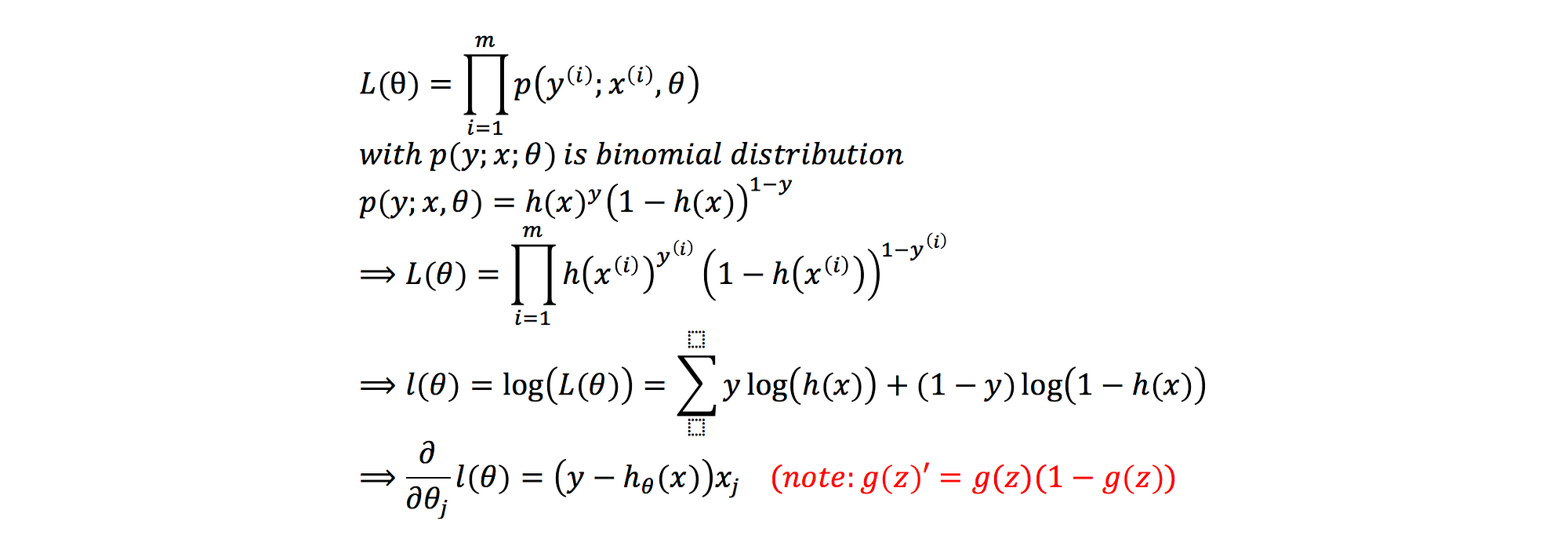
This therefore gives us the stochastic gradient ascent (log is concave function) rule:
It means, we pick the parameter that makes the observed data x most likely with when assuming output y =1.
Sigmoid function and Cross entropy cost function
Now, we have k labels instead of 2 labels in logistic regression. Let’s see how we chose the best one from k. Remind that the generalized linear model is defined in formal like this: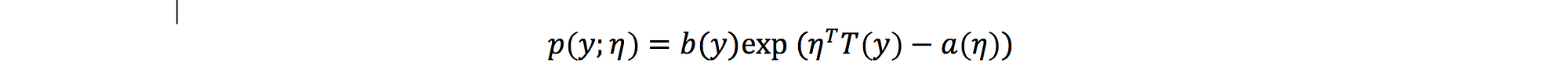
With multinomial distribution model, We define a vector y with k factors to determine a label is choosen or not.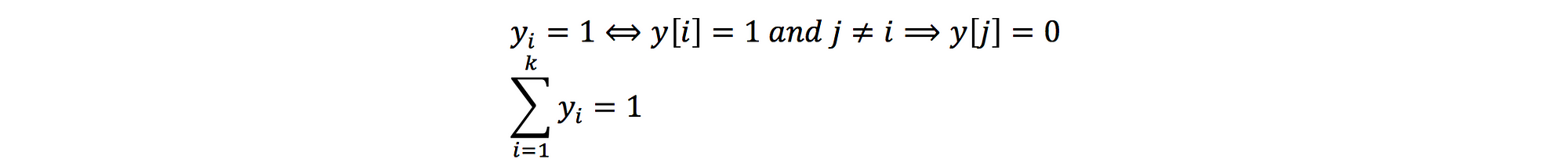
We have of probabilities of labels:
The probability density function or likelihood: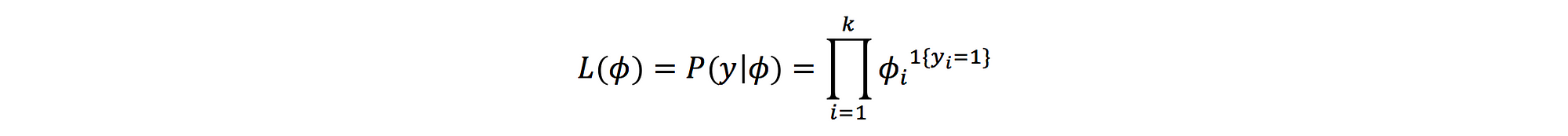
log likelihood: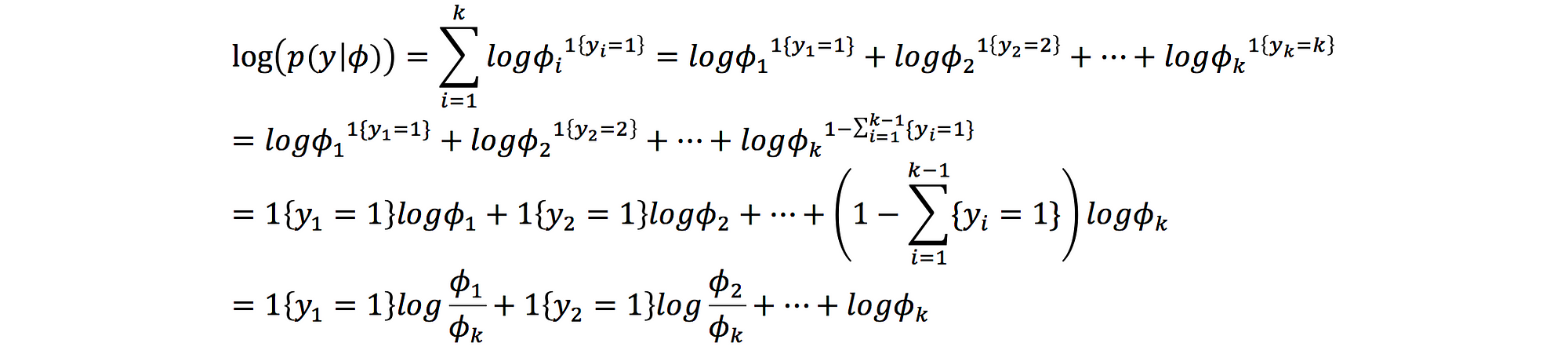
we assume that: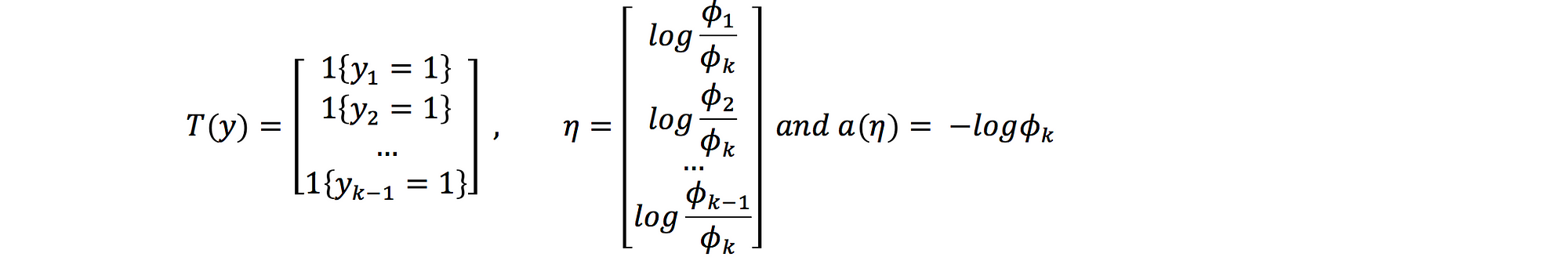
And reference to generalized linear model, we will have: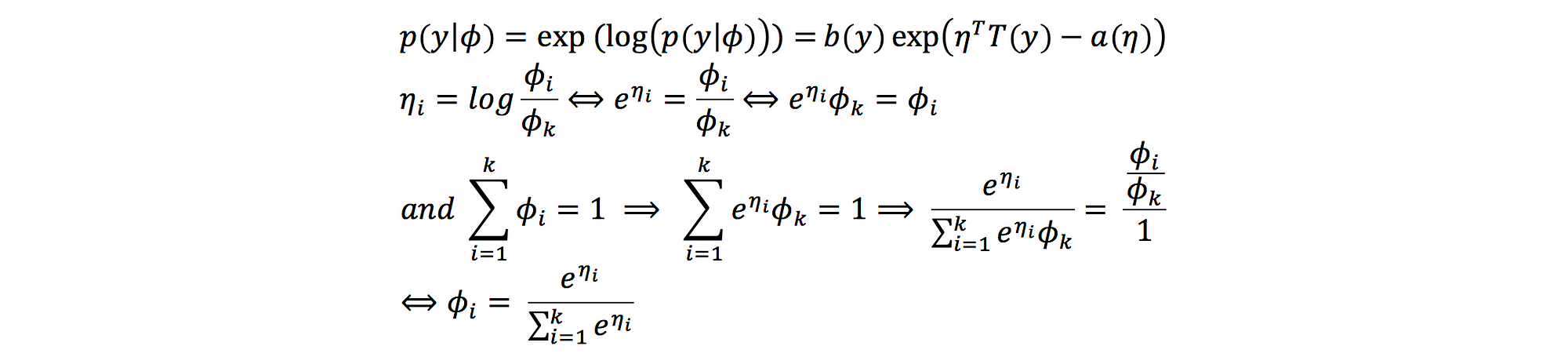
And the cost function: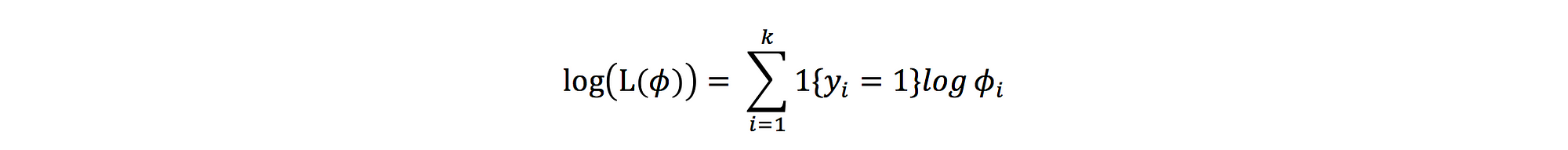
Sometimes, we see the similar one: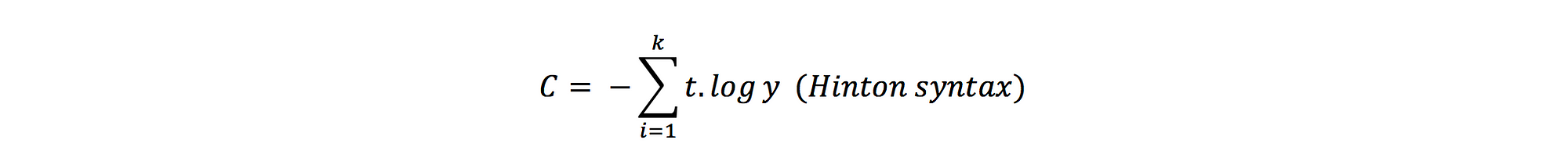
These points here are what I have learned and think they are fundamental and basic of a deep neural network.
Comments